Intro Skip Button
-
Can be done using Cross correlation and onset detection.
-
Some possible ways of doing this are
Audio Tagging
This is the most likely method. Netflix takes the audio sample of a show’s intro — Friends for example, and queries all the episodes to find where that audio sample appears. For accuracy they can apply conditions like only looking for the audio in the first 2 mins. To be even more accurate to make sure the intro’s beginning has the shows’ title for example, apply a little computer vision.
Machine Learning
The company is all about machine learning, from understanding what users like, don’t like, tracking behaviour, offering recommendations etc.
We can consider the possibility Netflix is learning just from the show Friends (or a base show) and teaching a machine to identify what an intro is without feeding it the audio sample or any visual cues.
So the machine learning algo will discover on its own to apply what it learned from Friends (a base show) to a show like Fraiser or The Office. It will identify an audio sample appearing on all episodes (pattern) around the same time (condition) mixed with some visual cues (condition) like the show’s title.
Audio Fingerprinting
Shazam
One of the first algorithms developed in the industry was developed by researchers from Shazam. Their solution is to identify the strongest peaks in the spectrogram, and to store the relative signatures of these peaks. The algorithm is illustrated in the image below:

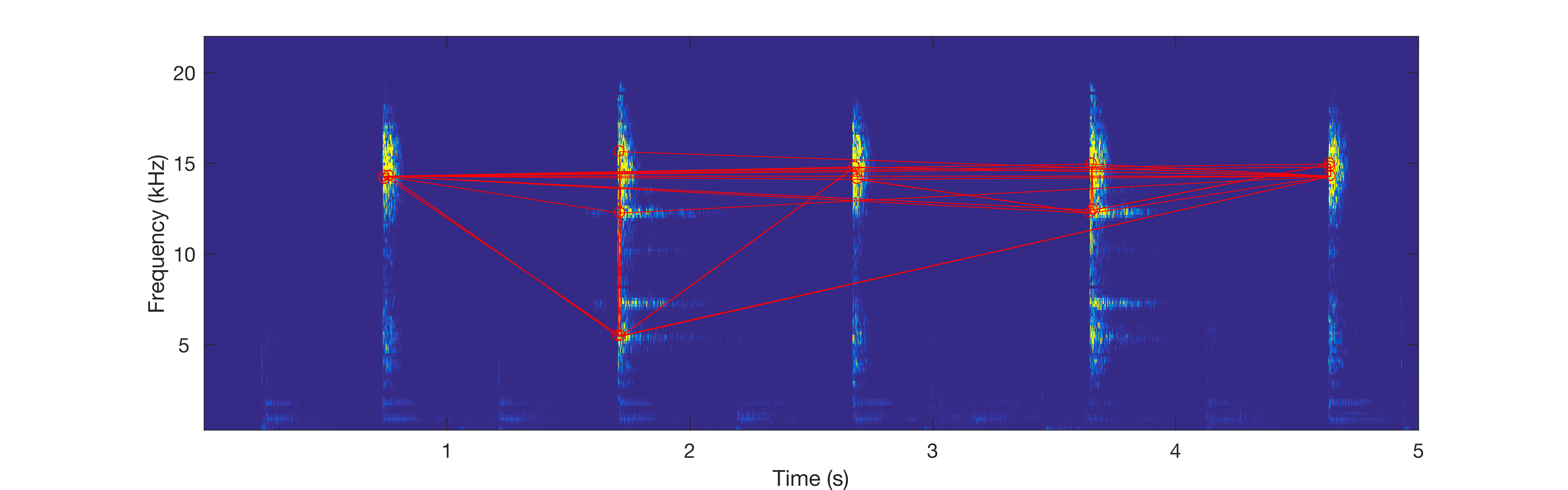
Red circles indicate the strongest peaks and red lines connect peaks that are close to each other. The result is a “spider web” over the spectrogram. The web is much sparser than the original spectrogram and can therefore be stored more efficiently. Furthermore, the web is robust to distortions like white noise, since that will have a relatively small impact on the strongest peaks. The web therefore acts like an audio fingerprint.
Some challenges remain. For instance, it is not immediately clear just how many peaks and connections we should store. The more intricate the web we create, the larger the dataset and the harder it is to compare with a reference. However, if the web is made simpler, the risk that it is impacted by noise increases, as well as the chance of a false positive: falsely reporting a match with a reference.
Furthermore, although many types of noise will not impact the strongest peaks, some distortions will shift or modify even the strongest peaks (for instance, low quality speakers). The web may also break if a strong burst of noise (for instance, someone talking) takes out an essential section.
Audio Matching
Once the fingerprints have been extracted, the next challenge is to identify the content to which the fingerprint belongs. This process is often called audio matching (although arguably, it should be called fingerprint matching). In order to perform the matching, we must first establish a reference database. Essentially, the reference database is acquired by extracting fingerprints from the reference content. The reference content may be pre-existing (e.g. a film), or could be a live feed (e.g. a TV channel). The size of the reference database will generally determine the solution architecture.